Introducción
El trabajo hace una revisión de la evolución espacio-temporal de la incidencia de la enfermedad COVID-19 en el Estado de Chiapas, México, a través del uso de modelos bayesianos espacio-temporales con tendencia
dinámica no paramétrica. El objetivo es evaluar la velocidad de propagación del virus, medida en términos de la tasa de incidencia acumulada de contagios, a lo largo de los municipios de la entidad y de seis meses de evolución de la pandemia.
La pandemia inicio en Wuhan, China, en noviembre de 2019, propagándose primero a Europa y después al Norte de América. Los primeros casos de COVID-19 en México se registraron el mes de febrero de 2020; posteriormente llegaron a Chiapas, donde
el primer caso positivo se registró en la ciudad de Tuxtla Gutiérrez, en marzo del mismo año . Se trató de una estudiante de 18 años, quien regresó de Italia luego del cierre de la escuela donde estudiaba, debido al incremento de casos
positivos de COVID-19 en el país europeo.
Con la finalidad de modelar con mayor veracidad la evolución de casos positivos de coronavirus en Chiapas, se utilizó la fecha de aparición de síntomas, reportada por los pacientes confirmados con COVID-19, en lugar de la fecha de ingreso
del paciente a la unidad de atención, debido a que puede existir un rezago temporal importante entre la aparición de síntomas y el arribo a la unidad médica.
La pandemia en Chiapas ha evolucionado de forma rápida, durante los meses analizados, alcanzó un total de 9,043 casos confirmados hasta el último día de julio, y se propagó en 98 de los 118 municipios del Estado. Es importante señalar que
la mayor incidencia de casos confirmados de coronavirus, ha ocurrido en los municipios con mayor densidad poblacional, como: Tuxtla Gutiérrez, Tapachula, San Cristóbal de las Casas y Comitán, en contraste con los 20 municipios señalados
de no presentar ningún contagio, debido, básicamente, a una combinación importante de factores entre los que se destacan las medidas de aislamiento social, los elevados niveles de aislamiento geográfico y las estrategias de prevención,
implementadas por los gobiernos Federal, Estatal y Local.
A pesar del incremento señalado en el número de casos confirmados, es importante señalar que las estrategias de prevención de la COVID-19 implementadas, han logrado contener, al menos parcialmente, la evolución natural de la epidemia (Ramos,
2020), lo que puede verse con claridad en la gráfica 1, donde desde el mes de mayo se observa una reducción continuada en la incidencia de casos de COVID-19 confirmados.
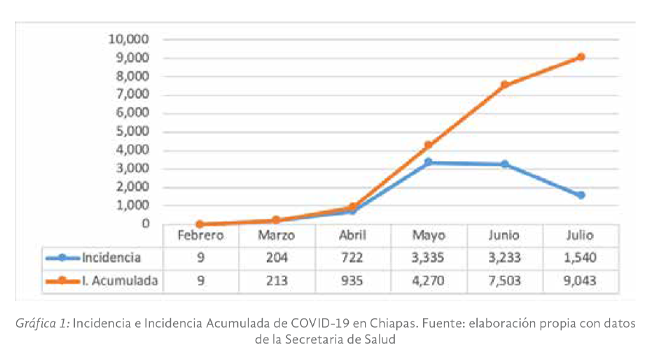
No obstante, la reducción observada en el número de nuevos contagios de la COVID-19 en la entidad, es importante señalar que, el riesgo de un nuevo brote está presente y que por tanto, se debe continuar con la aplicación de programas de control
de la pandemia, y con las medidas orientadas a detectar y atender oportunamente los casos positivos, lo que implica continuar brindando atención médica en toda la entidad, especialmente en los municipios con mayores niveles de vulnerabilidad
social y económica.
2. Materiales y Método
Los datos relativos a la evolución espacio-temporal de la COVID-19 en los municipios de Chiapas, fueron recopilados de la Base de Datos publicada por la Dirección de Información del Sistema de Vigilancia Epidemiológica de la Secretaría de
Salud de México. Los datos abarcan el periodo comprendido entre el 1 de febrero y el 31 de Julio del 2020. Se procesaron un total de 9,660 casos registrados, utilizando la fecha de inicio de síntomas reportada y asignando la entidad y
municipio de residencia del paciente (no el municipio donde se presta la atención). La incidencia de casos positivos de COVID-19 fueron agrupados y acumulados por mes, con lo que estimaron las tasas de incidencia e incidencia acumulada
por municipio.
Modelos espacio-temporales
Los datos espacio-temporales pueden definirse como una sucesión indexada, de manera que:
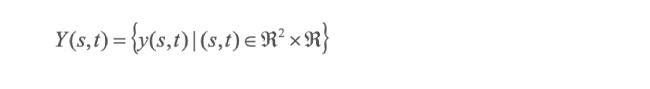
representa un proceso espacio-temporal indexado; donde y(s,t) es el valor observado en el punto s en n áreas espaciales, al tiempo t en T momentos (Blangiardo & Cameletti, 2015; p:235), por lo que, es posible representar fenómenos espacio-temporales
empleando modelos lineales (generalizados) con tendencia paramétrica en el componente temporal, al utilizar la función “identidad” como enlace de la variable predictora, definiendo en modelo:
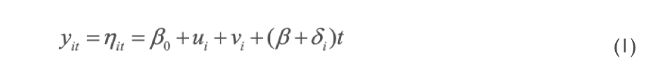
donde β0 representa la intersección o resultado medio esperado, mientras que las funciones ui y vi representan los efectos espacialmente estructurados y espacialmente no estructurados del área i. El efecto autoregresivo condicional intrínseco
ICAR(1) asociado al componente espacial estructurado, es modelado a partir de una distribución condicional dada por:
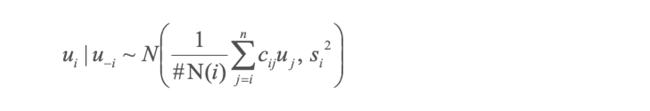
para toda i ≠ j, donde cij representa el criterio de vecindad; si cij = 1 las áreas i y j son vecinas, en caso contrario cij = 0, mientras que la varianza s
i2=σu2 / #Nidel área i, (Bivand et al., 2015) depende del número de vecinos N(i).
La especificación Besag – York – Molliè (BYM) de la varianza, utiliza la ecuación anterior para establecer implícitamente que la varianza de regiones con muchos vecinos será menor que la varianza de regiones con pocos vecinos, así, la especificación
de BYM supone que el componente espacial no estructurado vi tiene una distribución previa dada por vi ~ Normal (0, σv2), donde σv2 representa la variabilidad de los efectos aleatorios espaciales no estructurados, mientras que el parámetro
σu2 controla la variación entre efectos aleatorios espacialmente estructurados (Blangiardo & Cameletti, 2015).
En la ecuación (1), el parámetro β representa el efecto temporal global de todas las áreas, mientras δi representa la tendencia diferencial específica del área i al año t, por lo que δi se define como un parámetro “previo” intercambiable.
En general, los modelos espacio-temporales suponen la existencia de términos espaciales y temporales separables en el predictor lineal, por lo que la estructura de su matriz de covarianza puede separarse como el producto de: una matriz de
efectos espaciales puros y una matriz de efectos temporales puros (Martino & Rue, 2010), lo que da origen a cuatro tipos de interacciones que combinan efectos estructurados y no estructurados para las dimensiones espacial y temporal.
Modelos con tendencia dinámica no paramétrica
Los modelos de cohorte paramétrico como el definido por la ecuación (1) imponen restricciones sobre la linealidad del efecto temporal global (β) y la tendencia diferencial δi, en contraste con los modelos no paramétricos quienes permiten modelar
tendencias temporales utilizando formulaciones dinámicas a través de: efectos temporales estructurados ρt y efectos temporales no estructurados φt, (Rue & Martino & Chopin, 2009) utilizando la identidad como función liga:
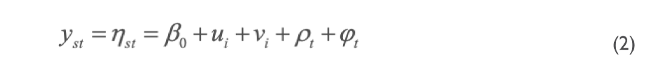
la tendencia temporal estructurada ρt se modelada dinámicamente utilizando una caminata aleatoria de orden uno (rw(1)) definida como:
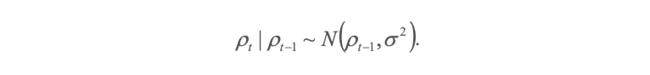
La tendencia temporal no estructurada φt tiene una distribución N(0, 1/τφ) (Schrödle & Held, 2011). Los componentes β0, ui y vi se definen como en el modelo (1).
Si, además de modelar de forma dinámica las tendencias espacial y temporal, se busca controlar la interacción espacio-tiempo, es necesario agregar un componente al modelo (2), para lo que se introduce el término γit, con lo que se obtiene
la siguiente especificación:
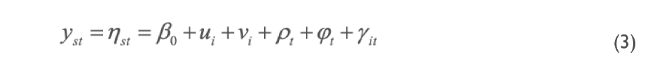
el efecto de interacción espacio-tiempo γit sigue una distribución gaussiana dada por: γit ~ Normal (0, 1⁄τγ) (Sharafifi et al, 2018). Los elementos restantes se definen como en el modelo (2).
Dado que el modelo (3) asume que la interacción espacio-temporal se presenta a través de un efecto espacial no estructurado vi y una tendencia temporal estructurada ρt, su matriz de covarianza espacio-temporal se escribe como el producto de:
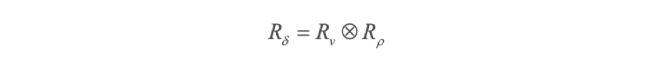
donde Rv = I y Rρ representa la estructura de vecindades especificada a través de la caminata aleatoria de primer orden y ⊗ representa el producto Kronecker.
Ajuste de modelos
Los modelos espacio-temporales: paramétrico (1), dinámico no paramétrico (2) y no paramétrico de interacción espacio-temporal (3), serán utilizados para ajustar los datos relativos a la incidencia acumulada de la COVID-19, durante los meses
de febrero a julio de 2020, para todos los municipios de Chiapas. Los datos comprenden el número de casos de COVID confirmados y referenciados al municipio de residencia, en la fecha en que el enfermo declaró que iniciaron sus síntomas,
de manera que la tasa de incidencia acumulada de coronavirus se estima como el cociente del total de casos confirmados de COVID-19, acumulados hasta el mes t, y el número total de casos esperados acumulados hasta el mismo mes, con lo que
se tiene:
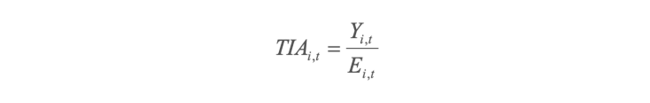
Lo que representa la tasa de riesgo de enfermar de COVID-19 en el municipio i, al mes t (Ebrahimipour, et al, 2016). Los casos esperados Ei,t representan el número total de casos que se esperaría ocurrieran, en el municipio i, al mes t, si
la población del municipio presentará el mismo comportamiento que el observado en la población estatal. La forma de calcular el número esperado de casos Ei,t es utilizando el método de estandarización indirecta, mismo que supone:
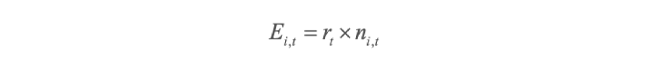
donde rt representa la tasa de incidencia acumulada de casos de COVID-19 en el Estado de Chiapas, al mes t; esto es, el número total de casos acumulados de COVID-19 dividido por la población total del Estado de Chiapas al mes t (Riebler, et
al, 2016). Por otra parte, ni,t representa la población total del municipio i al mes t.
Una vez estimadas las tasas de incidencia acumulada de COVID-19, para la totalidad de municipios de Chiapas, en los meses señalados, la incidencia acumula de casos de la COVID-19, se ajustará empleando los modelos (1), (2) y (3), presentados
en la sección anterior, para ello, se supondrá que los casos acumulados presentan una distribución poisson, es decir la ocurrencia de casos de COVID-19 presenta un comportamiento dado por Yi~Poisson(λi) donde
el parámetro λi representa la incidencia media de TIAi expresada como λi=Eiri, donde Ei representa el número esperado de casos acumulados de COVID-19 en el municipio i.
Los modelos espacio-temporales propuestos, se ajustarán considerando que los efectos espaciales y temporales son separables, además, el efecto espacial estructurado se ajustará usando un modelo ICAR, la tendencia temporal estructurada se modelará
utilizando una caminada aleatoria de orden 1, mientras que para los efectos no estructurados se supondrá que estos siguen una distribución normal independiente e idénticamente distribuida. En el caso de la estimación de parámetros e hiperparámetros
se utilizarán especificaciones previa vagas con el fin de evitar un sobre ajuste de los modelos.
La estimación de parámetros de los modelos propuestos fue hecha utilizando el paquete
Integrated Nested Laplace Approximation (INLA) desarrollado por (Rue et al 2009) e implementado en lenguaje de programación R. Este paquete permite hacer inferencias bayesianas rápidas y eficientes en modelos estructurales aditivos
(que forman parte de un conjunto más amplio de modelos Bayesianos jerárquicos) (Martins et al, 2013). El enfoque INLA es una alternativa menos costosa computacionalmente que el método tradicional MCMC.
Los resultados obtenidos de las estimaciones posteriores de los parámetros para los modelos (1), (2) y (3) que incluyen la estimación de: efectos fijos, se presentan en la tabla 1; efectos aleatorios se presentan en la tabla 2 y el mapa 1,
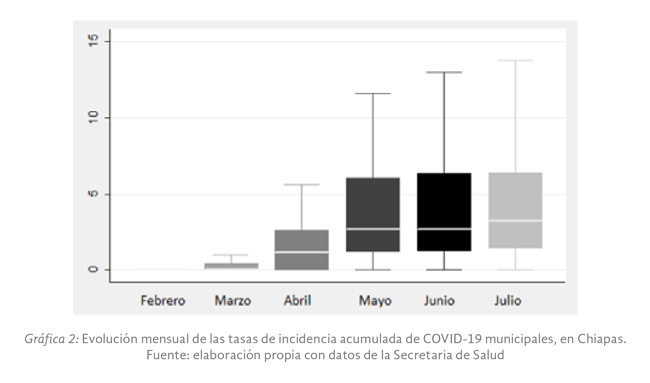
e incluyen los efectos temporales estructurados y no estructurados presentados en la gráfica 2; y distribuciones posteriores de los hiperparámetros presentados en la gráfica 3.
Calidad de ajuste de los modelos
Al momento se han propuesto tres modelos espacio-temporales: modelo paramétrico clásico (1), modelo dinámico no paramétrico (2) y modelo no paramétrico de interacción espacio-temporal(3). Una vez estimados los modelos (1) a (3) la forma de
identificar el modelo es través de criterio de información como el Akaike (AIC) o el Criterio de información de Desviación (DIC) donde valores más bajos son indicadores de un mejor ajuste, y una diferencia DIC de 3-5 se considera significativa.
(Lawson, 2015). El modelo con mejor ajuste debe tener un AIC bajo y un número efectivo pequeño de parámetros.
El modelo seleccionado será aquel que alcance el criterio de información de Akaike (AIC) más bajo, en términos de:
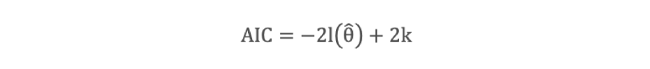
donde l(Θ^) es la función de máxima de log-verosimilitud y k es el número de parámetros del modelo (Blangiardo & Cameletti, 2015). El criterio DIC permite confirmar los resultados obtenidos.
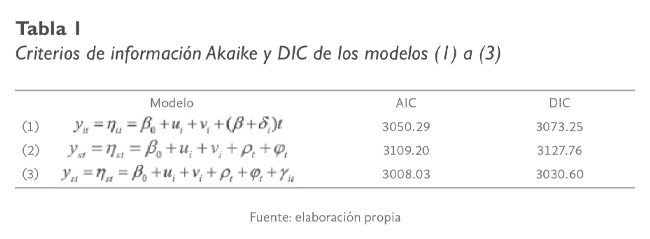
La tabla 1 presenta los criterios de información AIC y DIC para los modelos (1) a (3); en la misma se muestra que el modelo (3) que incluye un término de interacción espacio-temporal, cuya distribución previa es una caminata aleatoria de orden
1, presentó un AIC sensiblemente más bajo que los modelos restantes. De esta forma se utilizará el modelo no paramétrico de interacción espacio-temporal para modelar el comportamiento de las tasas de incidencia acumulada del virus SARS
COVID-19 en el estado de Chiapas.
Resultados
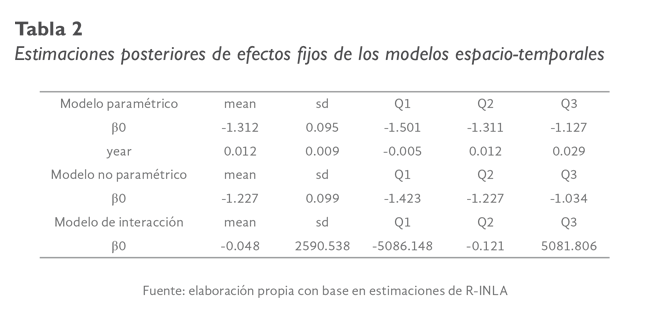
Los valores de las estimaciones posteriores de los efectos fijos para la media, desviación estándar y cuántiles realizadas a los modelos (1) a (3), se presentan en la tabla 1. El parámetro β0 representa el logaritmo natural del nivel medio
de la tasa de incidencia acumulada de COVID-19 para el estado de Chiapas, durante el periodo analizado, lo que equivale a un riesgo de exp(-0.048) = 0.953 para el caso el modelo no paramétrico de interacción espacio-temporal. Se debe señalar
que la tasa de incidencia acumulada promedio observada se estimó en 3.032, como puede verse en la gráfica 2.
La tabla 3 muestra las estimaciones posteriores de la media, desviación estándar y cuartiles de los efectos aleatorios de los modelos espacio-temporales (1) a (3). En el caso del modelo no paramétrico de interacción espacio-temporal, la media
de la densidad posterior del efecto espacial estructurado ui, es más pequeña que la presentada por el efecto espacial no estructurado vi, lo que muestra la importancia relativa del efecto de los contagios entre municipios.
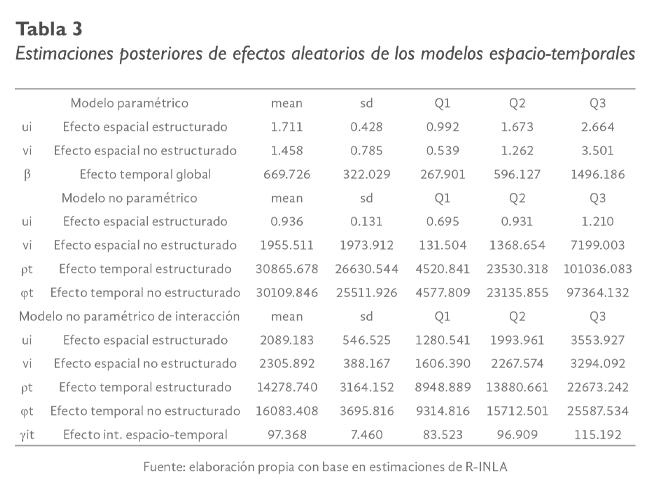
El valor medio estimado para los efectos temporales estructurados y no estructurados del modelo de interacción espacio-temporal, presentados en la tabla 3, muestra que las estimaciones de los efectos temporales son mucho mayores que las alcanzadas
por los efectos espaciales (estructurados y no estructurados), lo que hace evidente la mayor relevancia del tiempo (en relación con el espacio) como un factor explicativo fundamental para modelar la evolución de los contagios por el virus
COVID-19.
La variación observada entre los efectos temporales estructurados ρt y los efectos temporales no estructurados φt, donde la media de la densidad posterior de la precisión de los efectos estructurados es relativamente menor, que la estimada
para los efectos temporales no estructurados implica que la capacidad explicativa del modelo de interacción espacio-temporal debe tomar en cuenta la interacción de los efectos espaciales y temporales (Schrödle & Held, 2011). Esto se debe
a que las variaciones entre efectos espaciales y entre efectos temporales son relativamente pequeñas, comparadas con la variación entre efectos espaciales y temporales (ver tabla 3).
La media de la densidad posterior estimada para el término de interacción espacio-temporal γit resulta ser pequeña en relación con las medias estimadas para los efectos temporal y espacial (Martins et al., 2012), sin embargo, logra capturar
adecuadamente la dependencia espacial y la evolución temporal de las tasas de incidencia acumuladas de COVID-19.
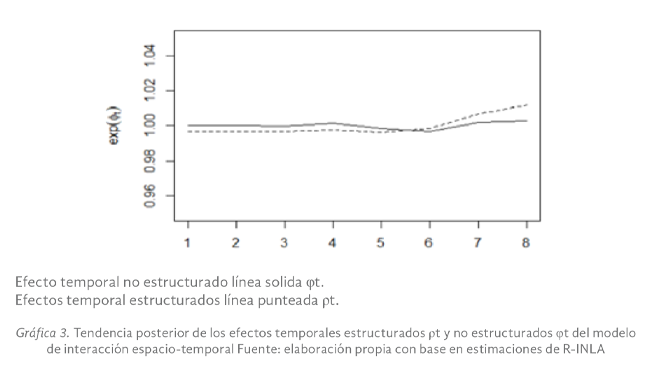
La Gráfica 3 presenta la tendencia posterior de los efectos temporales estructurados ρt y no estructurados φt del modelo de interacción espacio-temporal (modelo (3)), en la misma se observa que los efectos temporales estructurados inician
con valores por abajo de uno, no obstante, a partir del mes de junio el peso del efecto estructural comienza a crecer de forma sostenida, con lo que se puede esperar que, en los próximos meses, el efecto de las variaciones aleatorias temporales
tengan una menor incidencia sobre la evolución de los contagios por la COVID-19 en el estado de Chiapas.
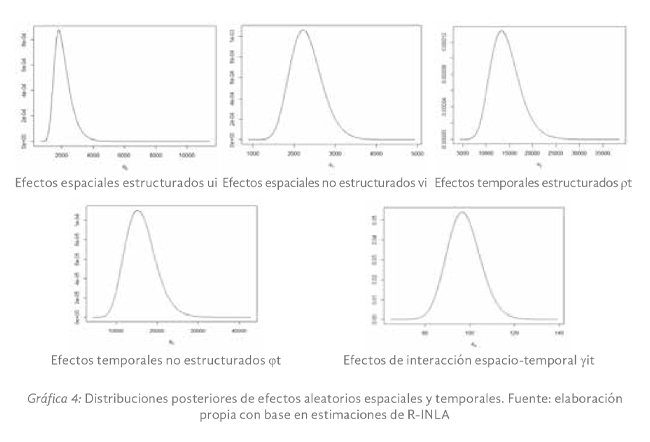
La Gráfica 4 muestra las distribuciones posteriores de los efectos aleatorios de los componentes espaciales y temporales, estructurados y no estructurados, además del efecto de interacción espacio-temporal del modelo (3). La estimación de
tales distribuciones permite estimar con gran precisión la probabilidad posterior de observar tasa de incidencia acumulada de COVID-19 mayores a uno.
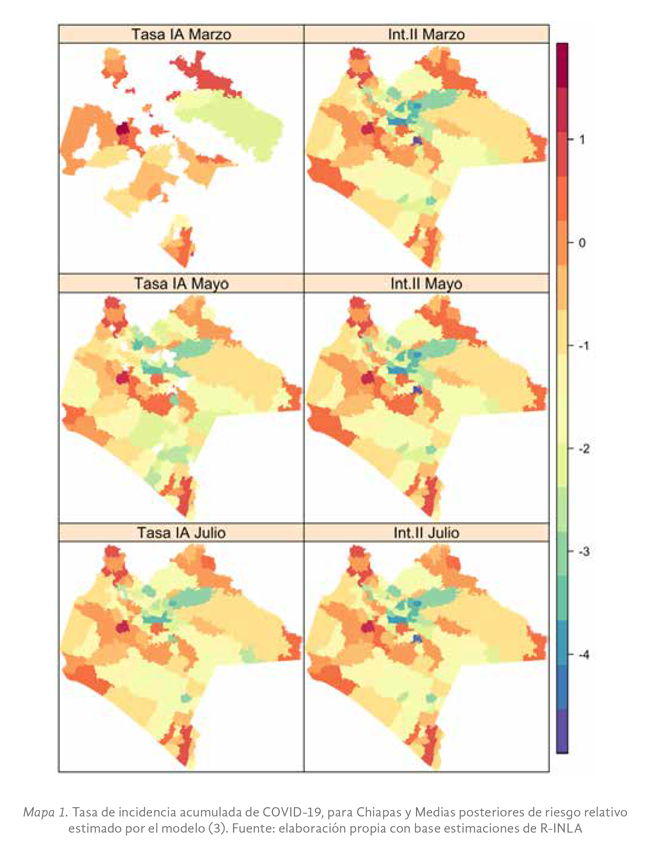
Las tasas acumuladas de incidencia de COVID-19, observadas durante los meses de Marzo, Mayo y Julio del año 2020 para los municipios de Chiapas, pueden observarse en el mapa 1, lado izquierdo, las mismas, muestran la ausencia de contagios
en un importante número de municipios durante el mes de Marzo. En los mismos mapas puede verse la evolución espacial y temporal del número de municipios que presentan contagios, así como el surgimiento durante los meses de Mayo a Julio
de un conglomerado de municipios con tasa de contagio por debajo del promedio Estatal (municipios en color azul).
La parte derecha del mapa 1, presenta información sobre la media posterior estimada, del modelo de interacción espacio-temporal, para la tasa de incidencia acumulada de COVID-19 en los municipios Chiapas para los meses de Marzo, Mayo y Julio.
Las tasas se presentan en escala logarítmica, para evitar un problema de sobre dispersión de los datos. En general, se puede ver que el modelo ajusta adecuadamente el comportamiento observado de las tasas y completa (interpola) el valor
medio de las tasas de COVID-19 en los municipios donde no se cuenta con información. Es importante señalar que los municipios con mayores tasas de incidencia acumulada de COVID-19 son: Tuxtla Gutiérrez, Tapachula y Reforma.
Conclusiones
A lo largo de este trabajo se han descrito y aplicado tres modelos espacio-temporales bayesianos jerárquicos ajustados con el paquete R-INLA con el objetivo de analizar la evolución de la tasa de incidencia acumulada de COVID-19 en los municipios
de Chiapas, entre los meses de Febrero a Julio. Es decir, se trata de un primer ejercicio de estimación que incorpora la interacción de efectos aleatorios espacio-temporales con el fin de estimar las variaciones mensuales a nivel municipal
de la tasa de incidencia de COVID-19.
Las técnicas de modelado espacio-temporal bayesiano existentes en R-INLA pudieron aplicarse exitosamente a la evolución de las tasas de incidencia acumulada de COVID-19, dada la disponibilidad y oportunidad de datos, lo que permitió analizar
las variaciones geográficas y temporales, además, dado que los modelos estudiados presentaron efectos aditivos, con un único efecto espacio-temporal, fue posible reducir el costo de cómputo asociado a la estimación.
Como puede observarse en el mapa 1, el municipio de Tuxtla Gutiérrez es el epicentro de la pandemia en Chiapas, lidera significativamente los casos diarios de infecciones por COVID-19, sin embargo, es seguido por los municipios de Tapachula
y Reforma, quienes registran un importante riesgo de contagio asociado. Los resultados presentados señalan que, en general, no son los municipios con mayor densidad poblacional quienes enfrentan las mayores tasas de contagio, sino que
la evolución espacio-temporal de la pandemia ha afectado de manera diferencial a los municipios de la entidad, protegiendo a aquellos que tienen mayores niveles de aislamiento geográfico y/o social.
Si bien, enfrentar la pandemia implica desde luego incrementar las capacidades del sistema de salud del Estado, es importante mencionar que la prevención y contención de los contagios puede resultar en una mejor estrategia, cuya orientación
debe incluir el detectar y aislar los casos observados, buscando con ello interrumpir el ciclo de transmisión del virus. A pesar de que los resultados indican una reducción paulatina y constante, la tasa de incidencia de COVID-19 (ver
gráfica 1), el número de municipios donde el riesgo de contagio es bajo ha disminuido también de forma sostenida durante los meses de estudio, lo que implica que pese a que se registran menos contagios, existe una mayor dispersión espacial
de COVID-19 (ver mapa 1) sobre el territorio chiapaneco.
Referencias
Blangiardo, M.; Cameletti, M. (2015) Spatial and Spatio-Temporal Bayesian Models with R-INLA. John Wiley & Sons: Chichester, West Sussex, UK.
Bivand, Roger & Gómez Rubio, Virgilio & Rue, Håvard. (2015). Spatial Data Analysis with R-INLA with Some Extensions. Journal of statistical software. 63.1-31.
Martino, S., Rue, H. (2010). Implementing Approximate Bayesian Inference using Integrated Nested
Laplace Approximation: a manual for the inla program. Disponible en
http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=0740AA9C1C62B6CF7A148F17015204B3?doi=10.1.1.142.3845&rep=rep1&type=pdf
Martins, G., Simpson, D., Lindgren, F., Rue, H. (2012). Bayesian computation with INLA: new features.
Norwegian University of Science and Technology Report.
Ebrahimipour, M.; Budke, C.M.; Najjari, M.; Cassini, R.; Asmarian, N. (2016). Bayesian spatial analysis of the surgical incidence rate of human cystic echinococcosis in north-eastern Iran.
Acta Trop. 163, 80–86.
Ramos C. (2020). Covid-19: la nueva enfermedad causada por un coronavirus. Salud Pública de
México. 2020;62:225-227. https://doi.org/10.21149/11276
Riebler, A.; Sørbye, S.H.; Simpson, D.; Rue, H. (2016). An intuitive Bayesian spatial model for disease mapping that accounts for scaling. Stat. Methods Med. Res. 25, 1145–1165.
Rue, H.; Martino, S.; Chopin, N. (2009) Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B (Stat. Methodol.), 71, 319–392.
Schrödle, B., Held L. (2011). Spatio-temporal disease mapping using INLA. Environmetrics 22 (6), 725-734.
Sharafifi, Z.; Asmarian, N.; Hoorang, S.; Mousavi, A. (2018). Bayesian spatio-temporal analysis of stomach cancer incidence in Iran, 2003–2010. Stoch. Environ. Res. Risk Assess. 32, 2943–2950.
Notas
1El estudio analiza la fecha de inicio de síntomas de COVID-19, los primeros casos reportados en Chiapas datan de inicios del mes de Febrero de 2020, de manera que los casos fueron agregados en periodos de 30 días, incluyen los
meses de febrero a julio.
2El caso de los datos espaciales referenciados a un área, a menudo se utilizan modelos lineales de efectos mixtos generalizados, dado que las variables se cuantifican en un número discreto de ubicaciones.
